EtherCrab 0.4: Distributed Clocks, io_uring, Derives, Oh My
EtherCrab 0.4.0
(lib.rs), the pure Rust EtherCAT MainDevice is out! I've added a
lot of features and fixes to this release, including Distributed Clocks support, an io_uring-based
network driver for better performance, and a brand new set of derive-able traits to make getting
data into and out of your EtherCAT network easier than ever! The full changelog including breaking
changes can be found here, but
for the rest of this article let's dig a little deeper into some of the headline features.
Are you looking to use Rust in your next EtherCAT deployment? Experiencing jitter or latency issues in an existing EtherCrab app? I can help! Send me an email at james@wapl.es to discuss your needs.
If you're interested in supporting my work on EtherCrab another way, please consider becoming a GitHub sponsor. I quit my job so I really appreciate any amount you can spare!
A quick note on terminology
The EtherCAT Technology Group (ETG) historically used the words "master" and "slave" to refer to the
controller of an EtherCAT network, and a downstream device respectively. These terms were changed by
the ETG recently to "MainDevice" and "SubDevice".The EtherCrab crate itself hasn't yet made this
transition, but will be doing so in a future release. This article uses "MainDevice" to refer to the
EtherCrab Client and "SubDevice" to refer to a Slave or SlaveRef.
Last thing I promise
Are you using EtherCrab in production or even just as a hobby? I'm collecting testimonials, so please let me know if you are! I'd love to know where and how EtherCrab is ending up!
I can be reached via james@wapl.es, @jamwaffles on Mastodon or @jam_waffles on Twitter. Do say hello!
Righto, onto the snazzy new features.
Distributed clocks
First up, Distributed Clocks (DC) support. I'm really proud of this feature because DC is complex to implement and verifying correct operation is challenging, but I got through all that, and EtherCrab now has support for Distributed Clocks! It's currently being used in the field and has solved a bunch of problems the user was having with their servo drives without DC enabled, which was great to see.
A quick intro to Distributed Clocks
If you're not familiar with EtherCAT's Distributed Clocks functionality, I'll give a quick intro here. Feel free to skip ahead if you don't need the refresher.
Distributed Clocks, or DC for short, is a fantastic part of EtherCAT that compensates for the fact that the clocks in every device in the network suffer from drift, phase noise and incoherence relative to each other. It is able to do this by designating a specific SubDevice as a reference clock and distributing (hah) that timebase across the network, taking into account propagation delays as well as continuously compensating for drift. EtherCAT networks with DC enabled can synchronise all SubDevice input and output latching to well within 100ns of each other if desired.
A SubDevice is much more likely to have a cleaner clock than the MainDevice as it doesn't suffer from OS noise like software interrupts, multiple CPU power states, core swapping and the like. This cleanliness is distributed to all other SubDevices, absolving the network of nearly all jitter, glitches or latency from the MainDevice when it transmits the PDI (Process Data Image).
A lot of applications don't need levels of timing this accurate (e.g. reading sensor data every half a second is pretty relaxed) but for SubDevices like servo drives in Cyclic Synchronous Position mode, it is vital to have a regular point in time where inputs and outputs are sampled. If the timing is even a little irregular, the drive can error out, or even cause damage to the plant.
Another common use case for DC is synchronising multiple axes of motion. If the outputs of each axis are not latched at the same time, deviations from the planned trajectory can occur. The global DC sync pulse coordinates these actions regardless of network size.
With DC, a SubDevice will buffer the PDI until the next DC sync cycle (SYNC0 pulse), at which time it will latch the input/output data. This gives a window of time in which the MainDevice can jitter, stall or go on smoko before it sends the next PDI without the SubDevice having to care, as long as the MainDevice sends the PDI before the next SYNC0 pulse.
DC in EtherCrab
As an example of the best possible performance, EtherCrab is capable of sub-10ns coherence between two SubDevices. The plot below shows the SYNC0 falling edge of two SubDevices aligned to within ~7ns of each other. The green trace exhibits a small amount of jitter as real life is never perfect, but still, seven nanoseconds!
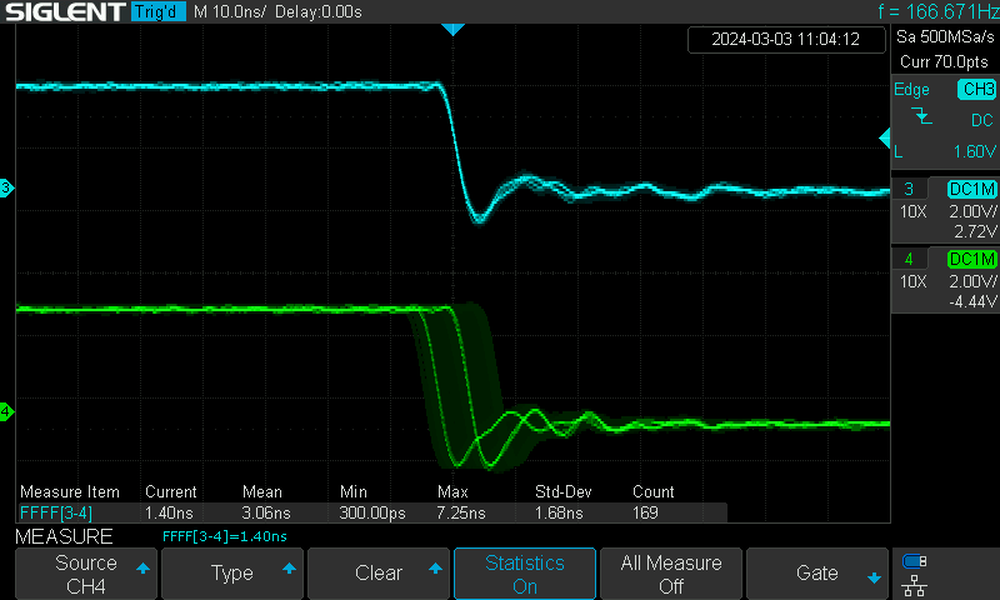
The MainDevice (EtherCrab) is responsible for repeatedly sending synchronisation frames to keep all SubDevice clocks aligned, as well as ensuring the Process Data Image (PDI) is sent at the right time within the DC cycle.
EtherCrab's new tx_rx_dc method will handle sending the sync frame alongside the PDI, but also
returns a CycleInfo struct containing some timing data that can be used to establish a consistent
offset into the process data cycle. Here's an example using smol timers:
let = PDU_STORAGE.try_split.expect;
let client = new;
let cycle_time = from_millis;
let mut group = client
.
.await
.expect;
// This example enables SYNC0 for every detected SubDevice
for mut sd in group.iter
let group = group
.into_pre_op_pdi
.await
.expect
.configure_dc_sync
.await
.expect
.request_into_op
.await
.expect;
// Wait for all SubDevices in the group to reach OP, whilst sending PDI to allow DC to start correctly.
while !group.all_op.await?
// Main application process data cycle
loop
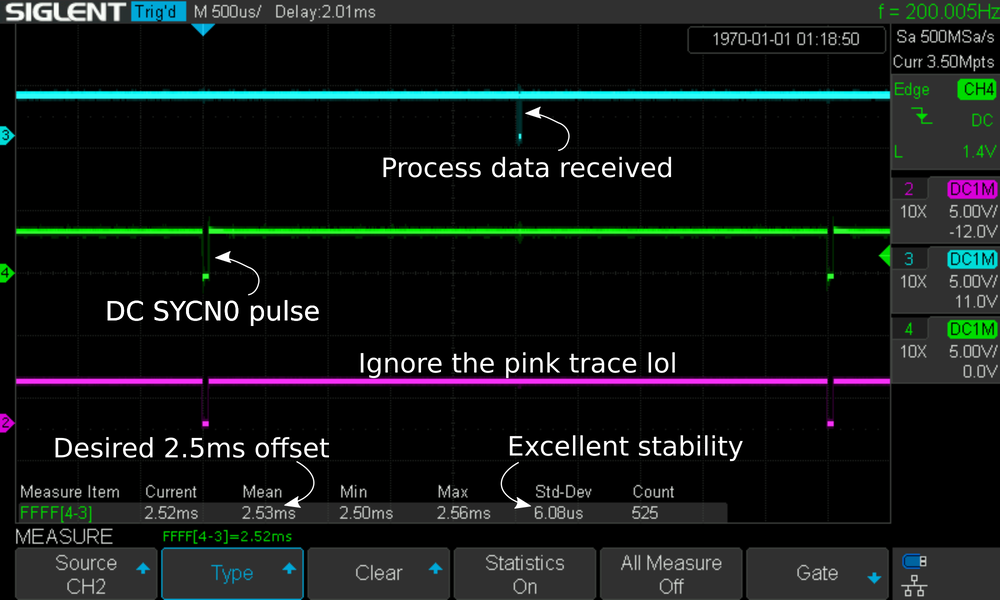
This example configures a 5ms DC cycle time, and will produce delay values that allow the MainDevice to send the PDI 2.5ms or 50% into the cycle. You can find a more complete example here. DC is tricky to get right, so the example is quite long.
It's important to use smol::Timer::at (or equivalent for your executor/blocking code) instead of a
naive delay to compensate for variable computation times in the loop. With the above code, we can
achieve extraordinarily low jitter from the MainDevice that fits well within the established DC
cycle:
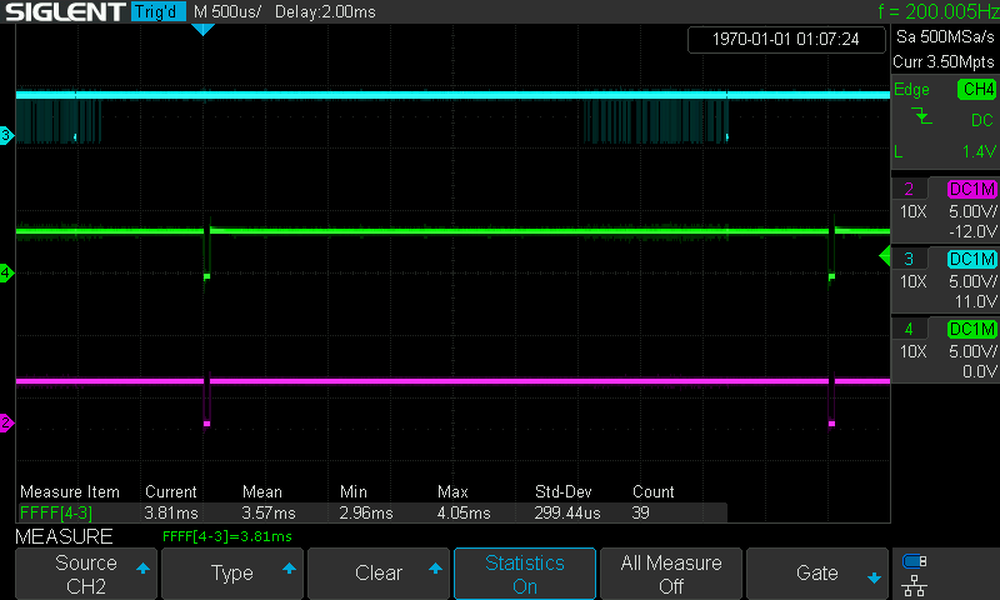
If you decide not to use the next_cycle_wait parameter, or you use tokio, the jitter will
look a lot worse. Notice the varying pulse offset on the cyan trace, as well as the atrocious
standard deviation of nearly 300us:
If you would prefer not to use async timers, I'd recommend the[timerfd crate]
(https://docs.rs/timerfd/latest/timerfd/) to get best timing accuracy. std::thread::sleep is also
an enticing option for its simplicity, but is a poor choice due to it not taking into account the
loop or network processing time.
io_uring
The Linux kernel introduced a new way of doing IO a while back called io_uring. It's touted as a
more perfomant way to do IO by using a pair of ringbuffers to reduce copies and overhead in the
system.
EtherCrab 0.4 adds support for io_uring using the blocking tx_rx_task_io_uring function. This is
similar to tx_rx_task, however the latter is async and requires an executor to run.
tx_rx_task_io_uring should be spawned into a new thread so as to not block the rest of the
application.
Async performance with smol is pretty solid, but for really tight timing, or applications with
short process data cycles, io_uring can reduce the TX/RX overhead, leaving a bit of breathing
room.
Additionally, because io_uring doesn't rely on an executor that might spawn other threads, we get
control over where the TX/RX driver is placed. For example, you might want to pin it to a core with
a specific realtime priority for best network performance. With an executor like smol or tokio,
you're at the mercy of that crate's thread creation and placement.
How it works
Whichever network driver is used, it needs to be efficient. Because EtherCrab is fully async
internally, we can use the Waker machinery provided by Rust to notify the driver when a frame is
ready to be sent, and allow it to sleep when no work needs to be done.
When the io-uring driver has been woken and the frame has been sent, it will busy-poll the response ring so as to not introduce unnecessary latency. This is a bit inefficient, but network packets are returned quickly enough that in reality not much time is spent busy looping.
If no more frames are ready to send, we simply call thread::park() to put the thread to sleep
until unpark() is called by a custom Wake trait implementation. Doing a bit of monitoring with
htop shows basically no CPU usage with a 1ms process data cycle which is great!
What we've done is essentially make a quite rigid, hyper specific futures executor that is tailored to our needs, namely latency and io-uring-ness. But. It works really well. I'll also add that it's not too difficult to write your own executor if there are some specific requirements you need.
Custom derives
EtherCrab 0.4 brings with it two new crates:
Getting data safely into and out of a process data image has been a challenge in EtherCrab so far,
largely relying on the user to add something like packed_struct. This is ok, but quite confusing
because EtherCAT is little endian, which packed_struct doesn't handle that well. The new crates
listed above provide a first-party, EtherCAT-tailored solution to this. The traits
EtherCrabWireRead, EtherCrabWireReadWrite and EtherCrabWireWrite as well as #[derive]s for
each are provided to make it easier to get named structs and other typed data into and out of
EtherCrab.
Here's a quick example using the derives:
let device = group.slave.expect;
let i = device.inputs_raw;
let state = unpack_from_slice?;
let ctl = DriveControl ;
ctl.pack_to_slice;
The traits are documented as experimental, however EtherCrab uses them internally and they've been working very well so far. There are already a bunch of type impls so it should just be a case of hooking them together in a struct for your application.
But why?
EtherCrab used to use a lot of packed_struct internally, however I was never happy with it. I
could not for the life of me get the byte/bit orders to where I could use sequential bit offsets.
For example, a 2 byte struct with 16 1 bit fields would require the use of bit indices like 8..15
for the first 8 fields, then 0..7 for the last 8, because EtherCAT is little endian. I might
just be holding packed_struct wrong, but it's also overcautious in its API, with nearly everything
returning a Result, and no real way of telling the compiler some things are infallible. With these
reasons in mind, I decided to write my own replacement.
Other solutions exist that use getters and setters, but due to how many different fields always need accessing within EtherCrab, I didn't want to add that level of noise to the code. They might be slightly more performant, but EtherCrab spends nearly all of its time waiting for the network anyway...
Safety over performance
As a subscriber to the great idea of the pit of success, these derives are meant to be as safe and easy to use as possible. This means things like zeroing out buffers before writing to them, and fallibly unpacking fields when decoding with length checks.
If you need to get rid of this overhead, #[repr(packed)] is always available, but more of a pain
to use both correctly and safely.
Honourable mention: multi-PDU sends
If two or more EtherCAT frames needed to be sent at once, EtherCrab 0.3.x would send these in two separate Ethernet frames. This is inefficient and became an issue when DC support was added. DC requires a sync frame to be sent alongside the PDI, and in 0.3.x this means doubling the amount of packets sent over the network, potentially tanking performance.
EtherCrab 0.4 now sends this sync frame next to the PDI frame, reducing overhead and improving cycle latencies.
There are other places in EtherCrab that don't yet use this functionality, but they're less performance sensitive than the application process data cycle.
Conclusion
EtherCrab 0.4 is the culmination of hundreds of hours of research, implementation and testing. It's full of improvements and some really useful new features as discussed above, and I'm really happy to see this stuff released!
The time it takes to develop also costs me money. If you'd like to see continued development on EtherCrab, I'd really appreciate you becoming a GitHub sponsor. I quit my job to work on EtherCrab, and could really use the support!
Either way, do please check out EtherCrab 0.4.0 on crates.io, lib.rs or GitHub.
The wire helpers crate is available here, and finally, why not take a look at some examples to get your Rust EtherCAT journey started?
If you get stuck, open an issue or say hi on Matrix. See you there!